A search engine provides easy access to information online, but Google web crawler/web spiders play a vital role in rounding up online content. Search engines organize the online content based on the web pages and the websites visible to them. Moreover, they are very essential for your search engine optimization (SEO) strategy. Google’s web crawlers scour online data and feed results to the machine so that they can be indexed for relevance on SERPs. If you want your site to appear on search engine rank pages, you must give Google bots something to crawl.
In this article, we talk about
- What is a Google web crawler?
- How does Google search work?
- How do Google robots crawl your website?
- Why Google web crawlers are important for SEO?
- What are the roadblocks for Google web crawlers?
- How to improve web crawling?
What is a Google Web Crawler?
Google web crawlers also referred to as Google bots, Google robots, or Google spiders are digital bots that crawl across the world wide web (www) to discover and index web pages for search engines such as Google, Bing, etc. Google doesn’t know what sites exist on the internet. Google search engine bots have to crawl websites and index them before they deliver the right pages for the right keywords, and phrases people use to search a page.
Let’s say, for instance, you go to a new store for grocery shopping. You might walk down the aisle and look at the products before you pick out what you need.
Likewise, search engines also use Google web crawlers as their helpers to browse the internet for web pages before storing that page data to use for future searches.
How does Google search work?
To better understand the Google web crawlers, firstly you must know how Google search generates web page search results.
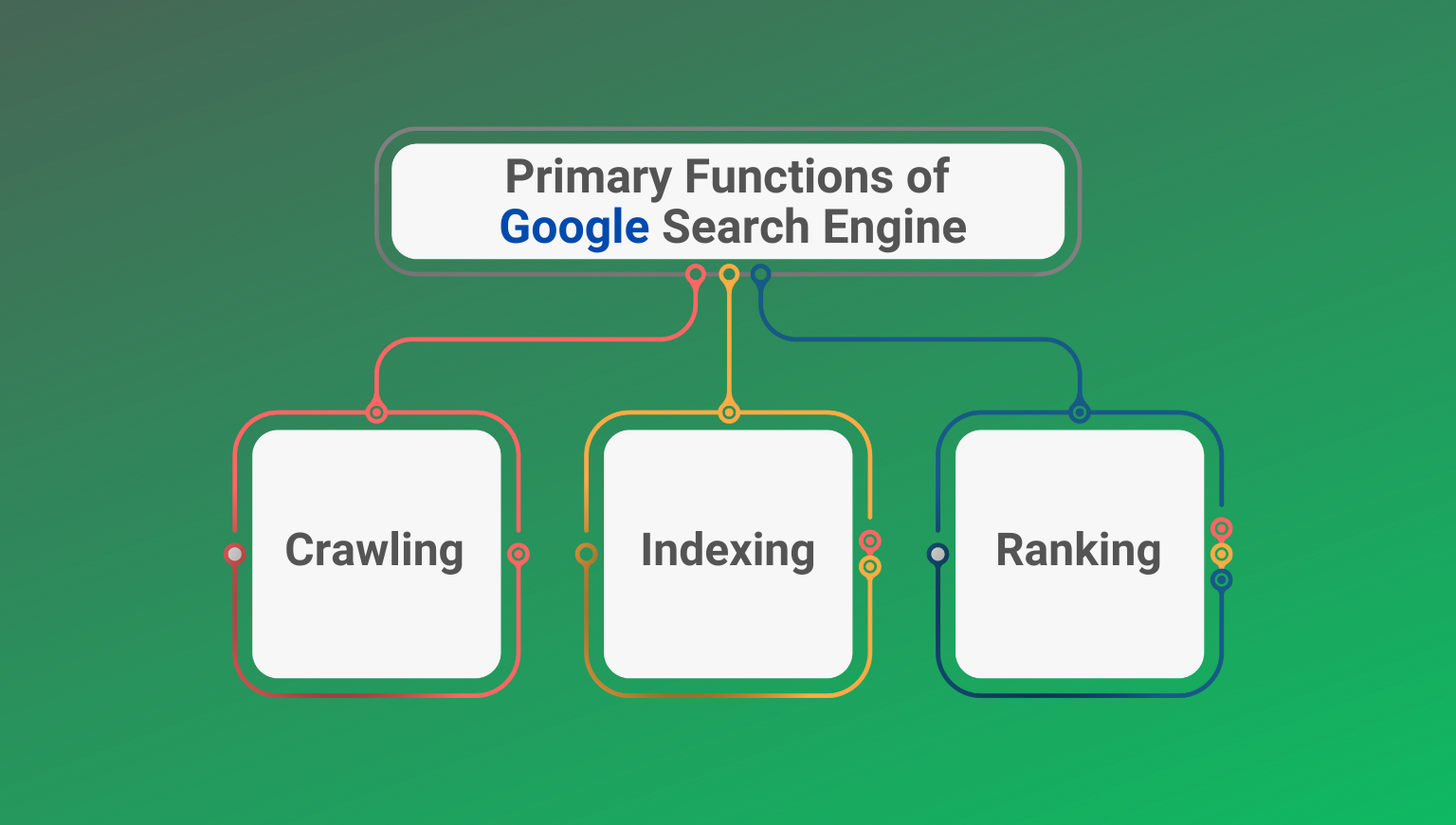
Google follows three main steps to generate these search results:
1. Crawling
Google web crawling means the search engine using Google robots to find out new content through a network of hyperlinks. The networking starts from an unknown page or through a sitemap.
2. Indexing
Once a page is found, Google tries to understand what it is about and stores that information into a gigantic database known as Google index. This process is called indexing.
3. Ranking
When a query is entered into the Google search box, Google finds the highest quality answers and then ranks them by the order of relevance, and finally serves them as a list called Search engine rank pages. The pages that appear on this list are highly ranked based on whether they offer the best answers while considering other ranking factors such as language, location, and devices.
How do Google robots crawl your website?
When you launch a new website, Google web crawlers will discover it eventually. The bots crawl through the texts, images, videos, and more. If you want Google web crawlers to find and index your site quickly, you must follow these three easy steps:
-
- Create a sitemap is a map that provides directions to the web crawlers for crawling. A Sitemap is uploaded to your root directory.
- Use Google webmaster tools to submit your website.
- Ask Google to index your website Search engines try to crawl every URL which comes in its way, so if a URL is a non-text file such as a video, or an image, it will not read that file if it doesn’t have any relevant filename & metadata.
Google search engines crawl the websites by passing between the links on the web pages. If your newly launched website doesn’t have links connecting your pages to others, you can ask Google search engines to crawl a website by submitting your URL on Google Search Console. Web crawlers act as an explorer in the new land. They are always hunting for discoverable links on pages and index them once they understand their features.
Remember, Google website crawlers only sift through public pages on sites, they can’t crawl through private pages. Private web pages where the search bots can’t reach are labeled as “dark web”. Google robots or crawlers, while they are on the page, gather useful information about the page, and then the web crawlers store these pages in their index. Google search algorithm helps to rank your website high for the users.
Why Google Web Crawlers are important for SEO?

SEO helps to improve your website for better ranking. SEO efforts are designed to help a site gain online visibility. For ranking your website higher on SERPs, it is important for your pages to be searchable and readable for Google web crawlers, Google bots, Google robots, or say Google spiders. Crawling is the first way Google search engines look for your pages, but frequent and regular crawling helps them display changes made on your website. Since crawling goes beyond the beginning of your search engine optimization campaign, you can consider web crawler behavior as a proactive measure for helping you appear first on the SERPs and improve your UX.
Without web crawlers to scour online data and verify that the content exists, all SEO efforts will be unproductive.
Crawl budget management
The amount of time that Google spends crawling a website is called as “site’s crawl budget”. The general theory of web crawling says that the web has infinite space, exceeding Google’s ability to explore and index each URL available online. As a result, there are limits to how much time Google web crawlers can spend time crawling any single website. Web crawling gives your new website a chance to appear in the top SERPs. You don’t get unlimited crawling from Google search engines. Google has a website crawl budget that guides its crawlers in – how often to crawl, which page to scan, and how much server pressure to accept. Heavy activity from web crawlers and visitors can overload your website.
To keep your website running smoothly, you can adjust web crawling through the crawl capacity limit and crawl demand.
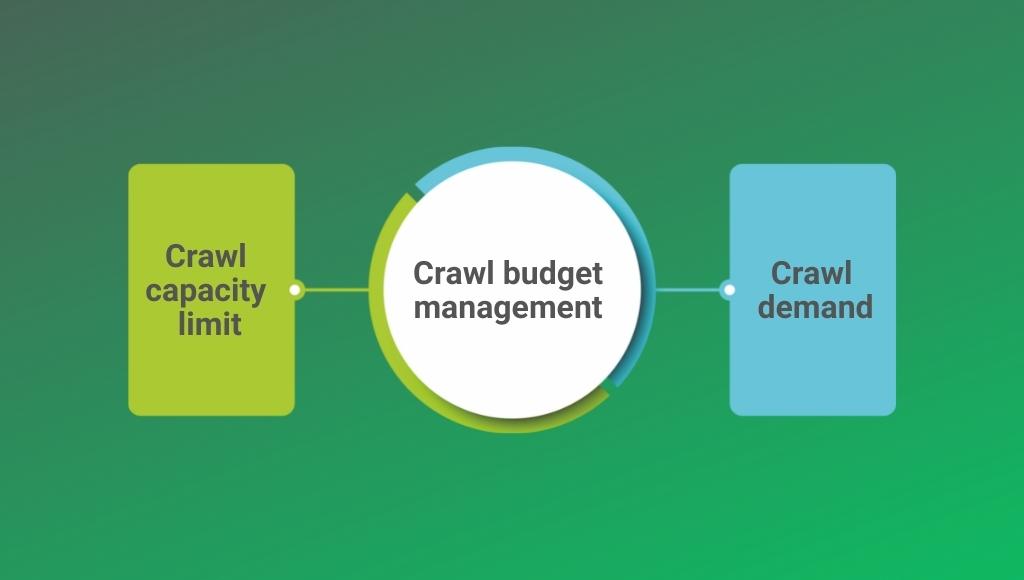
The crawl budget is determined by-
1. Crawl capacity limit/crawl rate limit
Crawl rate limit monitors fetching on websites so that the loading speed doesn’t suffer or result in a surge of an error. Google web crawlers want to crawl your site without overloading your server. The crawl capacity limit is calculated as the maximum number of concurrent connections that Google bots use to crawl a site, as well as the delay between fetches.
The crawl capacity limit varies depending on :
-
-
Crawl health
If your website responds quickly for some time, the crawl rate limit goes up, which means more connections can be used to crawl. If the website slows down, the crawl rate limit goes down and Google bots crawl less.
-
Limit set by the website owner in the Google search console
A website owner can reduce the web crawling of their site.
-
Google’s crawling limit
Google has so many machines, but they are still limited. Hence, we need to make choices with the resources we have.
-
2. Crawl demand
It is the level of interest Google and its users have in your site. If do not have huge followings yet, then Google web crawlers won’t crawl your site as often as the highly popular ones.
Here are three main factors that play important role in determining the crawl demand:
-
-
Popularity
-
Popular URLs on the Internet tend to be crawled more often to keep them fresh in the index.
-
-
Staleness
-
Systems want to recrawl documents frequently to pick up any alterations.
-
-
Perceived inventory
-
Without any guidance, Google web crawlers will try to crawl almost every URL from your website. If the URLs are duplicates and you don’t want them to be crawled for some reason, this wastes a lot of time on your site. This is a factor that you can control easily.
Additionally, events like site moves may increase the crawl demand to re-index the content under new URLs.
Crawl rate capacity and crawl demand together define the “site’s crawl budget”.
What are the roadblocks for Google web crawlers?
There are a few ways to block Google web crawlers from crawling your pages purposely. Not every page from your website should rank in search engine rank pages, these crawler roadblocks help to protect sensitive, redundant, irrelevant, or useless pages from appearing for keywords.
There are two types of roadblocks for crawlers:
-
-
Noindex meta tag
-
It stops the Google search engine from indexing and ranking a particular web page. You should apply the noindex to the admin pages, internal search results, and thank you pages.
-
-
Robot.txt file
-
It is a simple text file placed on your server which tells Google web crawlers whether they should access the page or not.
How to improve web crawling?
How long does it take for the Google search engine to crawl a website? It depends on the number of pages your website has and the quality of hyperlinks. To improve the site crawling you have to:
1. Verify that your website is crawlable
Google accesses the web anonymously and will be able to spot all the elements of your web page only if everything is in order. The first thing you should do to improve your web crawling is by verifying that search engines like Google can reach your website’s pages.
2. Create a solid homepage
If you ask Google to crawl your page, start from your homepage, as it is the most important part of your website. To encourage Google web crawlers to crawl your website thoroughly, make sure that your home page contains a solid navigation system that links to all key sections of your site.
3. Beware of links that violate the guidelines
You can improve your site crawling by linking your web page with another page that Google web crawlers are aware of.

How to calculate and optimize conversion rate for a website business is the question that is frequently asked by those Read more

What Is A Blog? A blog is an online journal or informational website displaying information in reverse chronological order. In Read more

We all know that search engines like Google, Bing, or Yahoo are serving millions of users per day who are Read more

If you are looking to start your own business, this article is for you. We will discuss here how to Read more