
Everybody loves “hacks.”
People keep finding hacks to make life easier. So, today I am going to share a legitimate SEO hack that you can start using right away.
Create a Robots.txt File to boost your SEO effectively! This small yet powerful text file, also known as a robot’s exclusive protocol, plays a vital role in guiding search engine bots. Although every website has a robots.txt file, it’s often overlooked. Designed to communicate with search engines, this file is an essential SEO tool that can significantly enhance your website’s performance.
Robot.txt file is one of the best methods to enhance your SEO strategy because:
-
- It is easy to implement
- Consumes less time
- Does not require any technical experience
- Increases your SEO
You need to find out the source code of your website, and then follow along with me to see how to create a robots.txt file that search engines would love.
What is a robots.txt file?

Robots.txt file is a simple text file that webmasters create to instruct web robots or web crawlers how to crawl pages on your website. Robots.txt file is a per of REP (robot’s exclusive protocol), a standard that regulates how robots crawl the website, access the index content, and serve that content to the users online. The REP also has meta robots or site-wide instructions for how search engines should treat the links such as “follow” and “unfollow”.
Robots.txt file indicates web crawlers which part of the website they can crawl and which part is not allowed to access. These crawl instructions are specified by “allowing” or “disallowing” for all user agents. Robots.txt file allows you to keep specific web pages out of Google. It plays a big role in SEO.
Search engines regularly check a site’s robots.txt file to see if there are any instructions for web crawling. These instructions are called directives.
Why robots.txt file is important for SEO?
From the SEO point of view, the robots.txt file is very important for your website. Using these simple text files, you can prevent search engines from crawling certain web pages from your website, they guide search engines on how to crawl sites more efficiently. It also tells search engine crawlers which web pages not to crawl.
For example,
Let’s say Google is about to visit a website. Before it visits the target page, it will check the robots.txt file for instructions.
There are different web components of the robots.txt file. Let’s analyze them:
-
- Directive – it is the code of conduct that the user-agent follows.
- User-agent – it is the name used to define specific search engine crawlers and other programs active online. This is the first line of any group. An asterisk (*) matches all crawlers except the Adsbot.
Let’s understand this with three examples:
1. How to block only Googlebot
User-agent: Googlebot
Disallow: /
2. How to block Googlebot and Adsbot
User-agent: Googlebot
User-agent: Adsbot
Disallow: /
3. How to block Adsbot
User-agent: *
Disallow: /
-
- Disallow – it is used to tell different search engines not to crawl a particular URL, page, or file. It begins with a “/” character and if it refers to a directory then it ends with a “/”.
- Allow – it is used to permit search engines to crawl a particular URL or website section. It is used to override the disallow directive rule to allow the crawling of a page in a disallowed directory.
- Crawl-delay – this is an unofficial directive used to tell web crawlers to slow down web crawling.
- Sitemap – it is used to define the location of your XML sitemaps to search engines. Sitemap URL is a fully qualified URL. A sitemap is a better way to indicate the crawlers which file Google can crawl.
Let’s understand this with the following example,
Say that Google finds this syntax:
User-agent: *
Disallow: /
This is the basic format of a robots.txt file.
Let’s understand the anatomy of the robots.txt file –
-
- The user-agent indicates for which search engines the directives are meant.
- “Disallow” directive in robots.txt file indicates that the content is not accessible to the user-agent.
- The asterisk (*) after “user-agent” means that the robots.txt file applies to all the web crawlers that visit the website.
- The slash (/) after “disallow” tells the crawlers not to visit any pages on the website.
But, why anyone would want to stop web robots from crawling their website? After all, everyone wants search engines to crawl their website easily so they increase site ranking.
This is where you can use the SEO hack.
If you have a lot of pages on your website, the Google search engine will crawl each of your website pages. But, the huge number of pages will take Googlebot’s a while to crawl. If the time delay is more it may hurt your website ranking. That’s because Google’s search engine bots have a crawl budget.
What is a crawl budget?
The amount of time that Google spends crawling a website is called as “site’s crawl budget”. The general theory of web crawling says that the web has infinite space, exceeding Google’s ability to explore and index each URL available online. As a result, there are limits to how much time Google web crawlers can spend time crawling any single website. Web crawling gives your new website a chance to appear in the top SERPs. You don’t get unlimited crawling from Google search engines. Google has a website crawl budget that guides its crawlers in – how often to crawl, which page to scan, and how much server pressure to accept. Heavy activity from web crawlers and visitors can overload your website.
To keep your website running smoothly, you can adjust web crawling through the crawl capacity limit and crawl demand.
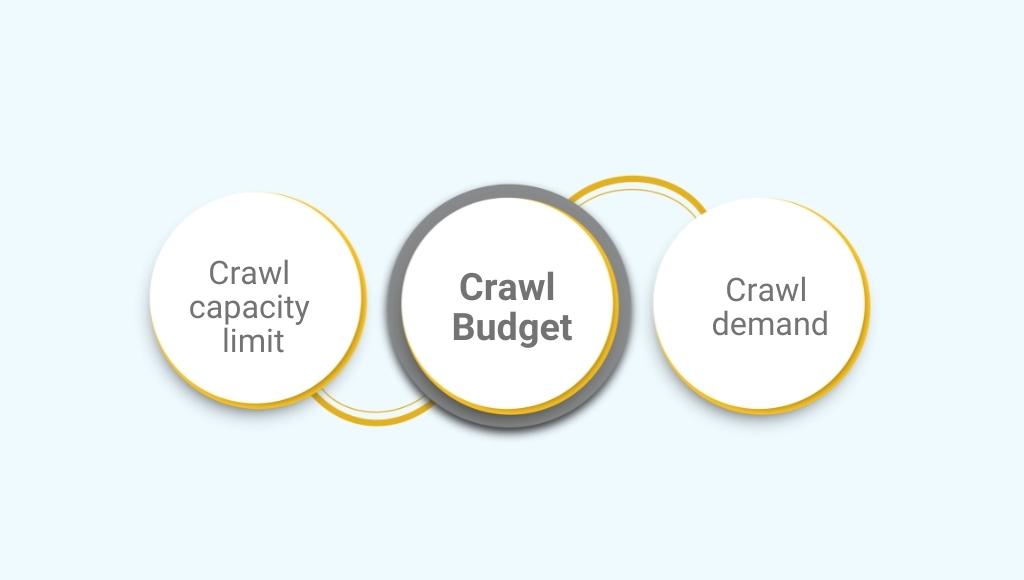
The crawl budget breaks down into two parts-
1. Crawl capacity limit/crawl rate limit
Crawl rate limit monitors fetching on websites so that the loading speed doesn’t suffer or result in a surge of an error. Google web crawlers want to crawl your site without overloading your server. The crawl capacity limit is calculated as the maximum number of concurrent connections that Google bots use to crawl a site, as well as the delay between fetches.
The crawl capacity limit varies depending on
-
-
Crawl health
-
if your website responds quickly for some time, the crawl rate limit goes up, which means more connections can be used to crawl. If the website slows down, the crawl rate limit goes down and Google bots crawl less.
-
-
Limit set by the website owner in the Google search console
-
A website owner can reduce the web crawling of their site.
-
-
Google’s crawling limit
-
Google has so many machines, but they are still limited. Hence, we need to make choices with the resources we have.
2. Crawl demand
It is the level of interest Google and its users have in your site. If do not have huge followings yet, then Google web crawlers won’t crawl your site as often as the highly popular ones.
Here are three main factors that play important role in determining the crawl demand:
-
-
Popularity
-
Popular URLs on the Internet tend to be crawled more often to keep them fresh in the index.
-
-
Staleness
-
Systems want to recrawl documents frequently to pick up any alterations.
-
-
Perceived inventory
-
Without any guidance, Google web crawlers will try to crawl almost every URL from your website. If the URLs are duplicates and you don’t want them to be crawled for some reason, this wastes a lot of time on your site. This is a factor that you can control easily.
Additionally, site-wide events like site moves may boost the crawl demand to re-index the content under new URLs.
Crawl rate capacity and crawl demand together define the “site’s crawl budget”.
In simple words, the crawl budget is the “number of URLs Google search engine bots can and wants to crawl.”
Now that you know all about the website’s crawl budget management, let’s come back to the robots.txt file.
If you ask Google search engine bots to only crawl certain useful contents of your website, Google bots will crawl and index your website based on that content alone.
“you might not want to waste your crawl budget on useless or similar content on your website.”
By using the robots.txt file the right way, you can prevent the wastage of your crawling budget. You can ask Google to use your website’s crawl budget wisely. That’s why the robots.txt file is so important for SEO.
How to find the robots.txt file on your website?
If you think finding the robots.txt file on your website is a tricky job. Then you are wrong. It is super easy.
This method can be used for any website to find its robots.txt file. All you have to do is to type the URL of your website into the browser search bar and then add robots.txt at the end of your site’s URL.
One of the three situations will happen:
1. If you have a robots.txt file, you will get the file just by typing www.example.com/robots.txt, where the example will be replaced by your domain name.
For instance, for www.ecsion-com-427748.hostingersite.com/robots.txt I got the robots.txt file as follows:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Sitemap: https://www.ecsion.com/sitemap_index.xml
If you find the robots.txt file you need to locate it in your website’s root directory. Once you find your robots.txt file you can open it for editing. Erase all the texts, but keep the file.
2. If you lack a robots.txt file, then you will get an empty file. In that case, you will have to create a new robots.txt file from scratch. For creating a robots.txt file you must only use a plain text editor such as a notepad for androids or a TextEdit for Mac. Utilizing Microsoft word might insert additional codes into the text file.
3. If you get a 404 error, then you might want to take a second and view your robots.txt file and fix the error.
Note: if you are using WordPress and you don’t find any robots.txt file in the site’s root directory, then WordPress creates a virtual robots.txt file. If this happens to you, you must delete all the texts and re-create a robots.txt file.
How to create a robots.txt file?
You can control which content or files the web crawlers can access on your website with a robots.txt file. Robots.txt file lives in a website’s root directory. You can create a robots.txt file in a simple text editor like a notepad or TextEdit. If you already have a robots.txt file, ensure you have deleted the text, but not the file. So, for www.ecsion-com-427748.hostingersite.com, the robots.txt file lives at www.ecsion-com-427748.hostingersite.com/robots.txt. The Robots.txt file is a simple and plain text file that follows the REP (robots exclusive protocol). A robots.txt file has many rules. Each rule either blocks or allows access for a given web robot to a specified file path on that site. All files will be crawled unless you specify.
Following is a simple robots.txt file with 2 rules:
1. User-agent: Googlebot
Disallow: /nogooglebot/
2. User-agent: *
Disallow: /
Sitemap: https://www.ecsion.com/sitemap.xml
This is what a simple robots.txt file looks like.
Let us see, what that robots.txt file means:
- The user agent named Googlebot is not allowed to crawl any URL that starts with http://example.com/nogooglebot/
- All the other agents are allowed to crawl the entire website.
- The website’s sitemap is located at https://www.ecsion.com/sitemap.xml
Creating a robots.txt file involves four steps:
- Create a file named robots.txt
- Add instructions to the robots.txt file
- Upload the text file to your website
- Test the robots.txt file
Create a file named robots.txt
Using the robots.txt file you can control which files, or URLs the web crawlers can access. Robots.txt file lives in the site’s root directory. To create a robots.txt file, you need to use a simple plain text editor like notepad or TextEdit. Use of text editors like a word processor or Microsoft will be void, as it can add unexpected characters or codes which cause problems for web crawlers. Ensure that you save your file with UTF-8 coding if prompted during the save file dialog.
Robots.txt rules and format:
-
- Robots.txt file must be named robots.txt.
- Every site can have a single robots.txt file.
- Robots.txt file must be located in the website’s root directory. For example, to control crawling on all the URLs of your website https://www.ecsion.com, the robots.txt file must be located at https://www.ecison.com/robots.txt. It can’t live in the sub-directory. (for example, at https://www.ecsion.com/pages/robots.txt ).
- Robots.txt file can be applied to the sub-domains or on non-standard ports.
- Robots.txt file is a UTF-8 encoded text file that includes ASCII. Google may ignore characters that are not part of the UTF-8 encoding, rendering robots.txt rules invalid.
Add instructions to the robots.txt file
Instructions are the rules for web crawlers about which part of the site they can crawl and which part they can’t. when adding rules to your robots.txt file keep the following guidelines in mind:
-
- Robots.txt file consists of one or many groups.
- Each group has different rules and directives, one instruction per line. Each group begins with a user-agent line that defines the target of the group.
- A group gives the following instructions to the user-agent:
- Who the group applies to (the user-agent)
- Which files, URLs, or directories the agent can crawl?
- Which files, URLs, or directories the agent cannot crawl.
- Web crawlers process the groups starting from the top to the bottom. A user agent can match only one instruction set, which is the first, most specific group that matches a given user agent.
- By default, a user agent can access any URL, or file on your website unless it is blocked by the “disallow” rule.
- Rules are case-sensitive. For example, disallow: file.asp only applies to https://www.example.com/file.asp, but not https://www.example.com/FILE.asp.
- “#” marks the beginning of a comment.
Upload the robots.txt file
After saving your robots.txt file to the computer, you might want to make it available for the search engine crawlers. How you upload the robots.txt file to your website completely depends on your server and the site’s architecture. You can search the documentation of your hosting company or directly get in touch with them.
Once you upload the robots.txt file, perform a test to check whether it is publicly accessible or not.
Test the robots.txt file
For testing your robots.txt markup, open a private browsing window in your web browser and navigate to the location of your robots.txt file.
For example, https://www.example.com/robots.txt
if you find the contents of your robots.txt file, you can proceed to test the robots.txt markup.
There are two ways offered by Google to test the robots.txt markup:
1. Robots.txt tester in search console
This tool can be used for robots.txt files which are already accessible on your website.
2. Google’s open-source robots.txt library
It is also used in Google search to test the robots.txt file locally on your computer.
Submit the robots.txt file
After uploading and testing your robots.txt file, Google’s search engine crawlers will automatically start utilizing your robots.txt file. There’s nothing much you need to do.
Conclusion
We hope this blog has given you an insight into why robots.txt files are so important for SEO. So, if you seriously want to improve your SEO, you must implement this teeny tiny robots.txt file on your website. Without it, you will be lagging behind your competitors in the market.

How to calculate and optimize conversion rate for a website business is the question that is frequently asked by those Read more

What Is A Blog? A blog is an online journal or informational website displaying information in reverse chronological order. In Read more

We all know that search engines like Google, Bing, or Yahoo are serving millions of users per day who are Read more

If you are looking to start your own business, this article is for you. We will discuss here how to Read more